
From .NET Framework to .NET Core and Linux, the story so far
Two years ago, Seq was an entirely .NET Framework 4.5.2, Windows-specific codebase.
This week we took the wraps off of our first preview release of Seq running 100% natively on Linux under Docker.
In between, Seq has continued evolving - we released a whole new analytic query engine, rewrote dashboarding, added alerting, and redesigned the signal bar. But, in a background thread, we’ve been persistently working towards cross-platform compatibility.
Starting out on this path there were a lot of unknowns, and an obvious mountain of work ahead. If you’re about to set off in this direction, too - or have already embarked - I hope you can take some ideas (and comfort!) away from this short post explaining the process we used to get a working codebase across the line.
First step, taking care of the libraries
I think the TL;DR version of this article is one insight: it’s easier to complete the messy last-mile port (we’ll come to that part later) if you’ve already created working, battle-tested, cross platform versions of anything you possibly can.
For Seq, this meant porting:
- Libraries within the solution itself - any low-hanging fruit in the solution was made to compile against .NET Core by converting to the new CSPROJ format and adding an additional
netstandard**ornetcoreapp**moniker to the<TargetFrameworks>element - Libraries we could extract - we pulled out our new parser construction library Superpower and shipped it as OSS on GitHub, targeting .NET Standard from the beginning
- Libraries we help to maintain - work to move Serilog and its sinks and extensions started in mid-2015; helping the community effort to get these libraries across eventually made our own platform port much smoother
Since .NET Standard libraries can be used by .NET Framework code, these could be integrated into the app, tested, and used immediately. Probably a textbook use case for .NET Standard, but worth calling out that it worked as advertised for Seq. Being able to target .NET Standard while running on .NET Framework is a really wonderful feature of the .NET tooling.
Taken individually, each little library or dependency seemed insignificant in comparison with the last-mile task of porting, but put together, having stable and tested cross-platform libraries reduced two important measures when the last-mile port began:
- The time from switching targets to having compilable code; compilable means refactorable and unit-testable, so progress from the point that everything compiles is much smoother, safer, and more incremental than hacking at a completely broken codebase
- Sources to go hunting around in for bugs when things don’t work as expected - it was much nicer knowing, with some certainty, that a problem was in the code we were porting rather than an external library
Like most .NET apps, Seq stands on the shoulders of a vast ecosystem of libraries from NuGet and elsewhere. By mid-2016, we had a pretty good idea which of our dependencies were going to make the transition to .NET Core smoothly, and where we were going to have to do more work.
Exploring the state of .NET Core deployment
With a good grasp on where we stood with respect to the .NET Core and .NET Standard APIs, the next major unknown was packaging and deployment.
.NET Core was attractive for Seq from the beginning because of the deployment model; instead of having to keep Seq compatible with the different .NET Framework versions running on everyone’s desktops and servers, through .NET Core we can deploy the runtime and framework components that we depend upon with the product itself, which is much more testable and supportable.
How this would work in practice, combined with Windows Installer and the various target operating systems, was still an unknown, so first we built and released clef-tool, a tiny .NET Core command-line app complete with its own MSI-based installer, and then Piggy, a .NET Core CLI like clef-tool, but this time targeting macOS and Linux in addition to Windows.
Solving the problems we uncovered (and writing up the experience) helped shift more work out of that critical last-mile.
At around the same time, we moved some of our own internal infrastructure to a self-contained ASP.NET Core app running on Linux and Docker. This did a lot to increase our confidence in the stability and robustness of the .NET Core stack.
Building the portable event store and query engine
On Windows, Seq has historically used ESENT for managing raw data on disk. Since ESENT is a Windows component, we knew from early on that a replacement would be needed if Seq was to run on other operating systems.
Back in Seq 4.1, we went from “the storage engine” to “an IStorageEngine”, and included an alternative implementation based on LMDB. Doing this we ended up with a dependency graph like:
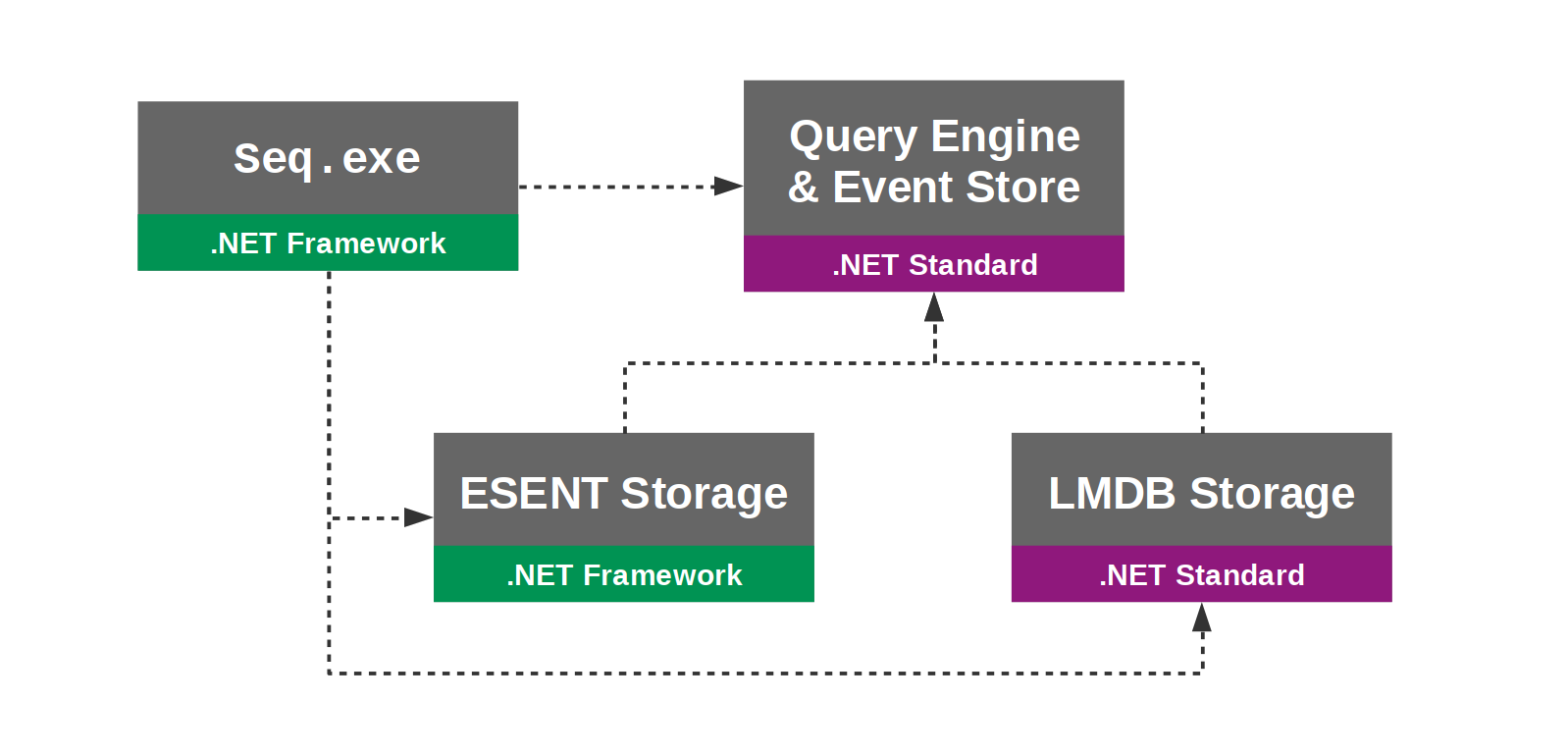
So, we were able to maintain a Windows-only, .NET Framework-based ESENT back-end, while moving the query engine, event store, and new LMDB-backed storage over to portable .NET Standard libraries ready to run on Linux or macOS.
This might all make a bit more sense if you keep in mind that, while Seq uses ESENT or LMDB for reliably persisting and retrieving byte[] events from disk, all of the filtering and query language, sharding across extents, caching and so-on is implemented at a higher level, by Seq itself. select count(*) from stream group by time(1h) executes mostly the same code path regardless of how events are being persisted.
The test harness for all of this was an ASP.NET Core “mini Seq” that just ingested and retrieved events, running on .NET Core and Linux. More portable code created and tested, more bugs ironed out.
Breaking the AppDomain dependency
The least pleasant task, which I must have subconsiously avoided until almost the last minute, was figuring out what to do with Seq’s plug-in app mechanism.
Apps were implemented as .NET assemblies, each loaded into the Seq process in their own AppDomain, set up carefully so that predictable versions of shared libraries like Newtonsoft.Json, Seq.Apps and Serilog would be found, while other libraries used by Seq itself could be kept out of the way.
There were two big problems to solve:
- Besides the apps on NuGet that we know about, customers using Seq today have written all kinds of apps for their own purposes, and there’s no chance at all that they’ll successfully run, unmodified, on .NET Core
AppDomainisolation is not supported on .NET Core (TheAppDomaintype is still around, but the ugly and complex hosting features have been left out - kudos to the .NET Team for seeing this change through)
The solution we deployed in Seq 4.2 was to host apps in their own processes. This means that Seq running on .NET Core on Windows can create a .NET Framework process to host an app, without reintroducing any .NET Framework dependencies in the Seq codebase itself. You might spot Seq.Apps.GenericHost.exe running on your server - it’s a simple .NET Framework app that loads the plug-in assembly and feeds it events sent over STDIN from the parent Seq process.
On Linux and macOS, the same generic host process is used, but this time running on .NET Core. Apps that use Windows or .NET Framework-only features won’t work, but so far we’ve had a high success rate running popular apps like Seq.App.Slack unmodified.
Although most Seq apps will use the generic host process, the new app runner can host any executable as a Seq app. This opens up possibilites like writing Seq apps in non-.NET languages. The C# API is still the most portable way to write a Seq app, but we think the plain-executable approach will be a big plus in companies using Seq from other, non-.NET languages.
Hosting apps in separate processes also opens up some great opportunities for us to improve the app mechanism in the future: processes are easier to properly isolate than AppDomains, and we can one day monitor and report on the I/O, CPU and memory cost of each running app precisely. I’m really looking forward to exploring the full extent of improvements made possible by this change.
The last mile
By the time we came to shift the main Seq executable to .NET Core, we’d already done a lot of groundwork. I hope I haven’t set any expectation so far that we applied a novel strategy to this part of the process: if so, I’m afraid you’ll be disappointed.
In early January, we started with our partially-portable Windows/.NET Framework based solution, switched all of the executable projects to target netcoreapp2.0, and started fixing compilation errors. We used #if liberally to exclude broken code, and once the mountain of errors was diminished to a small hill, put priority on getting our unit tests and end-to-end test runner working.
I took us until the end of January before we had a runnable but deeply broken Linux build; we still had to replace several non-portable components - service hosting, a NuGet client, the metadata store, not to mention migrating our entire API to ASP.NET Core - and invested a lot of time into solid cross-platform CI and testing.
In spite of this, it’s really impressive how much code “just worked” on .NET Core 2.0. The larger API surface area supported by .NET Core and .NET Standard 2.0 eliminates the low-value churn that was required when porting code to earlier versions.
We had a lot of fun on the way, and found some challenging problems to solve; Ashley Mannix has written in detail about our 5.0 development environment and codebase over on the Seq blog.
Conclusions
At the time I’m writing this, we have an early preview release available to try on Docker Hub, which to me is pretty amazing given it’s only two months since we forked from the Seq 4.2 release branch.
Preparation really paid off for us - it’s been much easier to bring a smaller, incremental milestone in on time, than it would have been to keep a large development milestone on track.
From here to “RTM” is no doubt also going to be a very interesting time; I’m looking forward to sharing some updates as we go.