
Good citizenship - logging from .NET libraries
Operating a large system can be a substantial challenge. Is everything working, for some definition of “working”? If not, what’s going wrong?
Many of us use log events as the primary source of answers to these questions. Done well, log events are among the best instrumentation we’ve got. But, implemented poorly, log events can be practically useless — and even introduce more problems to solve.
When consuming libraries or frameworks that publish log events, quality counts. The difference between average and great logging is most noticeable at the critical moments when service is degraded or bugs need to be fixed.
As a framework author, it's important not only to log, but to look at where those logs go and how they can be looked at.
— David Fowler (@davidfowl) July 10, 2017
This got me thinking - what should we be looking for? Below, I’ve collected a few simple things library authors can do to help. I’m writing this from the perspective of working in .NET, but I’m sure most of these considerations apply whether you’re writing code in C#, Java, Ruby, or Go, etc.
1. Identify the source
This principle serves two goals. First, when an engineer finds an interesting event in the log, they need to trace that back to its origin. Since your component may be integrated as a binary, this isn’t always just a matter of grepping the project files. The event itself needs to carry this information.
Second, managing log volume is a big part of every ops environment. If a component — like yours — is too noisy, its events need to be programmatically “turned down” or filtered from the stream.
In practice, this usually means adopting type-specific loggers that attach a source name to each event. Using Serilog:
var log = Log.ForContext<SomeType>();
log.Information("Hello, world!");
// -> Event carries `SourceContext` value `MyLibrary.Namespace.SomeType`
Level control and filtering usually relies on the namespace hierarchy to select messages, e.g. SourceContext like 'MyLibrary.%'.
2. Don’t expose ILogger
I log, you log, we all love to log… but don’t make us play which ILogger is this? When multiple libraries all expose their own logging abstraction called ILogger, picking the right one in the ReSharper/IntelliSense “resolve type name” list is an annoying chore.
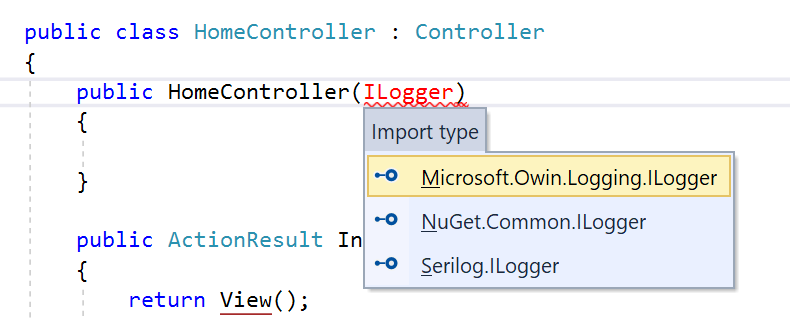
Unless your library is a general-purpose logging library, choose a specific name for your logging abstraction: IMyLibraryLogger or something equally distinctive. Better yet, use LibLog and avoid the need for yet another logging abstraction entirely.
3. Accept the user’s choice of logger
Let’s face it, we’ll probably never all agree on one “perfect” logging implementation. We’ve all got different needs, priorities, and tastes. Don’t try to drag everyone back to the bad-old-days of log4net dependencies everywhere (and incompatible versions of log4net dependencies, at that).
Libraries and frameworks should log to an abstraction, preferrably a widely-used and well-supported one such as Common.Logging or Microsoft.Extensions.Logging, or ideally, use the invisible abstraction provided by LibLog.
4. Error when you catch, not when you throw
Most of the time, it’s not up to a library to decide what constitutes an error vs. what’s just an expected part of day-to-day operation of a system. When your library throws an Exception, it doesn’t have much context at all about what the application is actually doing. Log some debug information about what generated the error, but leave it up to application code to record the exception in the log with all of the useful contextual data.
Excessively generating errors is a sure-fire way to mask the important ones.
If your library or framework catches an exception at the outermost level — perhaps it was thrown by a user-supplied handler or callback — by all means do log an error at this point.
5. Build correlation in
Frameworks that orchestrate units of work — for example the handling of a web request or the multiple steps of an authentication workflow — should provide an identifier that groups all log messages generated during that unit of work.
var request = // Request received
using (LogContext.PushProperty("RequestId", request.Id))
{
log.Debug("Dispatching request to {Handler}", handler);
handler.Invoke(request);
}
Here, both the Debug event from the framework, and any log events published by the handler, will be tagged with the same RequestId. This vastly improves the experience of lining up related events when debugging later on.
6. Name your placeholders
Many of us live on structured logging. Even if you don’t, your library or framework will play much better with applications that do if you support structured events.
This is made a lot easier by LibLog and by Microsoft.Extensions.Logging: both of these abstractions accept structured events using message templates:
log.Information("Hello, {Username}!", username);
// -> Structured event with `Username` property
Importantly, these logging abstractions transform named placeholders back into old-fashioned {0} and {1} if the user’s chosen logger doesn’t support structured logging.
Here’s a nicely-templated message directly out of ASP.NET Core MVC:

You can see how the ActionName, Arguments and ValidationState embedded into the message are all first-class properties of the event. Those names come from tokens in the message template:
Executing action method {ActionName} with arguments ({Arguments}) - ModelState is {ValidationState}
7. Retain the event type
Those of use using structured logging also rely heavily on event types to make sense of large log volumes. In Serilog and other libraries based on message templates, the event type is implied from the format string.
So, two events generated from the following logging statement will share the same event type, derived from the string "Hello, {Username}!":
log.Information("Hello, {Username}!", username);
The almost-equivalent version below doesn’t have this property, however:
log.Information("Hello, " + username + "!");
From the logger’s perspective, each event generated using string concatenation will have a different event type that depends on the value of username, so the set of related events can’t be easily identified to find or exclude them en masse.
8. Use higher logging levels sparingly
When assigning levels to events, think from the perspective of the application, not from the perspective of the library. Even Information-level events should rarely be raised by library or framework code. Which handler is configured to receive a message might seem important to you, as author of a messaging framework, but in the context of a large-scale application this stuff is just noise, and should be assigned a Debug-type level or below.
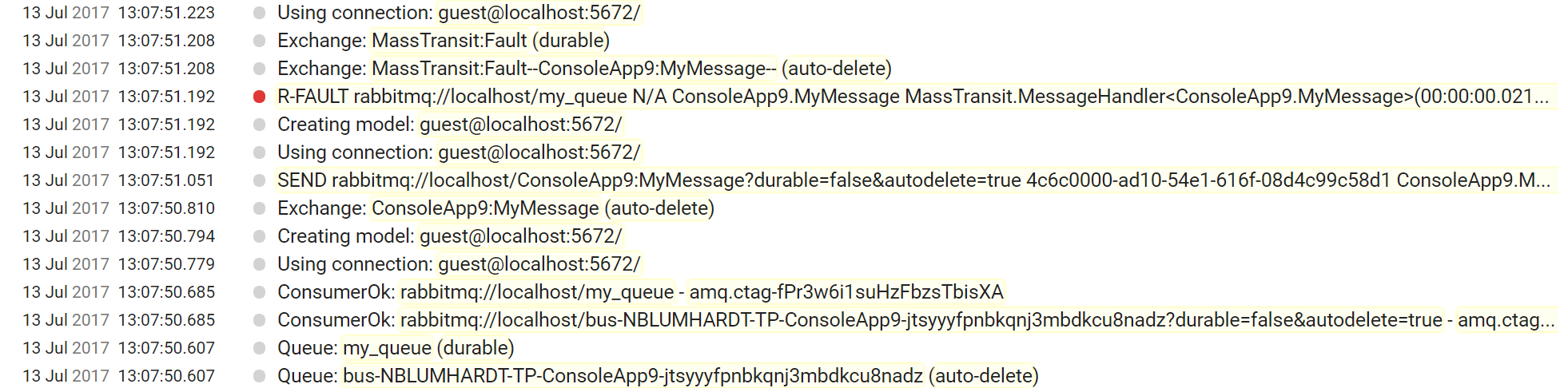
MassTransit gets this exactly right: I had to turn on debug-level logging just to confirm I’d hooked up the logger correctly:
9. Don’t.
Finally, if you can avoid the need for logging by protecting invariants and returning useful information directly back to calling code, you can skip this checklist ;-)
Checklist
In summary:
- Identify the source
- Don’t expose
ILogger - Accept the user’s choice of logger
- Error when you
catch, not when youthrow - Build correlation in
- Name your placeholders
- Retain the event type
- Use higher logging levels sparingly
- Avoid logging at all, if you can
None of these are absolutes, and I’ll bet there are many more useful guidelines I’ve missed. If you’ve got a point to add, please speak up in the comments :-)