
Exception Triage
Collecting errors and exceptions from production is perhaps the most fundamental way for devops to improve quality, but only if someone actively investigates the output. I’ve worked in several teams who’ve followed this trajectory:
- Start collecting errors and exceptions with something like Serilog and Seq
- Ride a wave of enthusiasm as previously-undetected bugs are found and fixed
- Reach the state where most exceptions are now the commonplace, understood, or non-exceptional variety
- Struggle to find real issues in a sea of uninteresting data
- Never open that view/signal/Slack channel again :-D
The big problem is that there’s no magic tool to sort the wheat from the chaff — the signal from the noise — for you. Staying on top of exceptions is a lot like staying on top of email: along with supporting tools, you still need discipline to pull it off.
Here’s the recipe I use; I hope you’ll share your own experiences and help me to refine the approach.
1. Collect exceptions in context
I’ll use the terms error and exception interchangeably, but of course they may not always be the same thing (you can log an error event with no associated Exception, and you can log an exception at a Warning, Information or Debug level).
The trick to staying on top of exceptions is to be able to tell one from the other. This means taking extra time to ensure the exception record explains what was happening when the exception was thrown. You might not be able to modify pre-existing code, but when new code is written you should do whatever you can to give yourself a fighting chance.
Don’t:
catch (Exception ex)
{
Log.Error(ex, "An error occurred");
}
Do:
catch (Exception ex)
{
Log.Error(ex, "Failed adding item {ItemId} to order {OrderId}", item.Id, order.Id);
}
The message template "Failed adding item {ItemId} to order {OrderId}" distinguishes this particular logging statement from others like it elsewhere in the codebase. If every catch block produces something like "An error occurred", you’ll have to work much harder to decide whether you’ve seen an exception before.
Telling errors apart is half the problem. Deciding when two errors are essentially the same is the other half. The type, message and stack trace help with this, but properties attached to error events like ApplicationName, RequestPath, MessageType and so-on play a big role.
- A lot of context can be attached to an exception record using the
LogContextand various enrichers. - A handy trick, possible since C# 6, is to use an exception filter to log the exception at the point it is thrown, rather than at the point it is caught. This will improve your chances of including contextual information in the event. You can see this in action in the Serilog middleware example for ASP.NET Core.
- SerilogExceptions is a Swiss Army Knife enricher that intelligently organizes data from many well-known exception types.
Notice that in the example code, the exception itself is passed as the first (Exception) parameter. Don’t try substituting the error message for the log message:
Log.Error(ex.Message);
Although the exception message itself might have some of the information we added above, like item and order ids, this is now an essentially un-structured log event. The message may vary slightly even when the cause is the same ("Order 5 has no delivery date", "Order 6 has no delivery date", …), so we can no longer use event types to zero in on the exceptions generated by this line of code. Serilog Analyzer can pick up this and other similar usage problems at development time.
2. Separate new exceptions from all exceptions
This is where things get interesting. First, you need to isolate the raw material. I use a signal in Seq called Errors and Exceptions that includes both, because I use this one to get a feel for the volume of exceptions occurring whether they’re logged at the Error level or not.
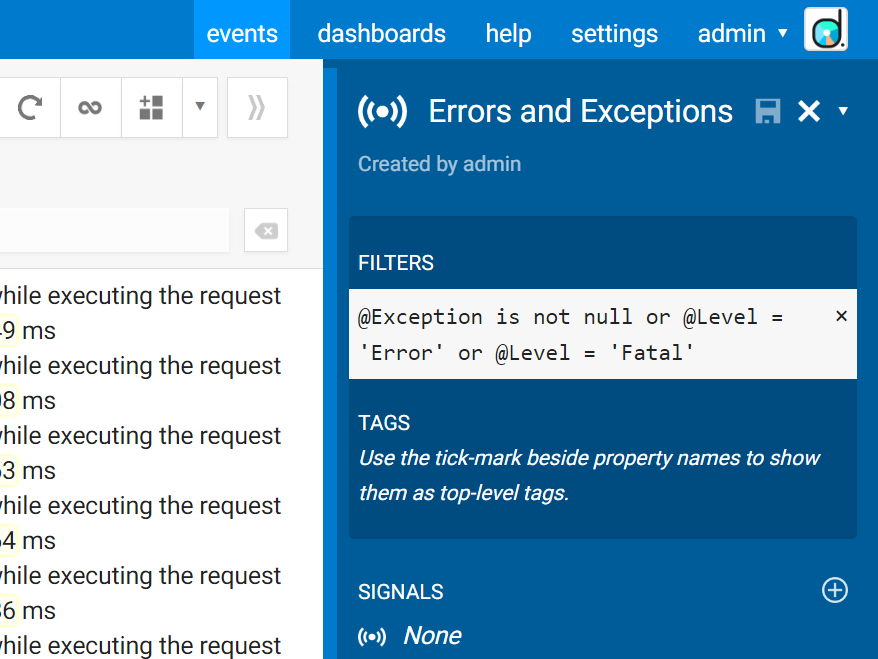
(You should probably take an interest in this too, but it’s more likely that you’ll view it in aggregate on the dash — or a Seq 4 dashboard! — than read each matching event individually.)
The second signal to create is Triage Required. Selecting this in combination with Errors and Exceptions will show you all of the “new” exceptions that you need to deal with. Initially, the Triage Required signal won’t include any fiters, so you’ll see a lot of events there waiting for attention.
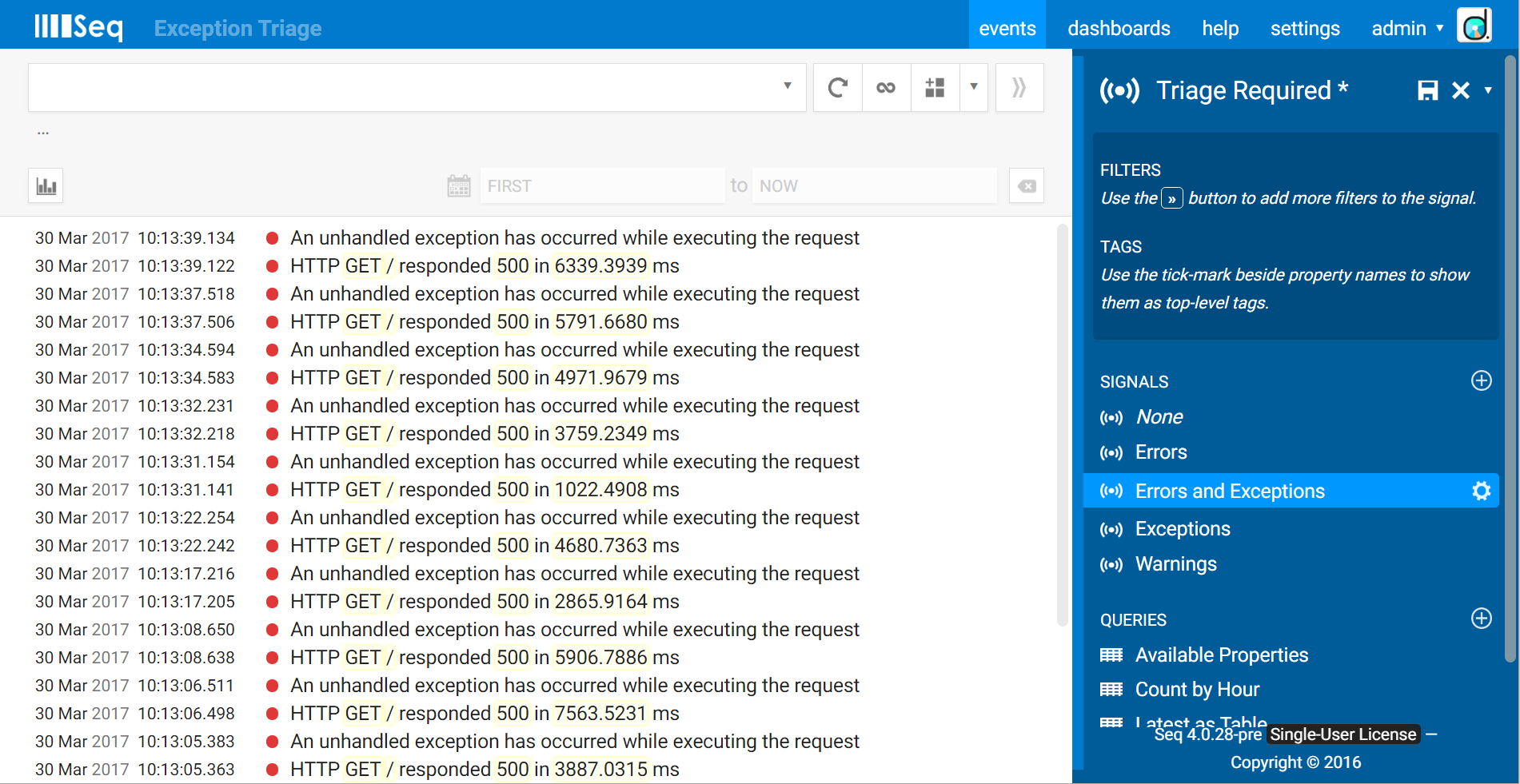
3. Exclude triaged exceptions
Triage is the process of evaluating a new exception to decide what action should be taken to resolve it. Start with the first one on the list:
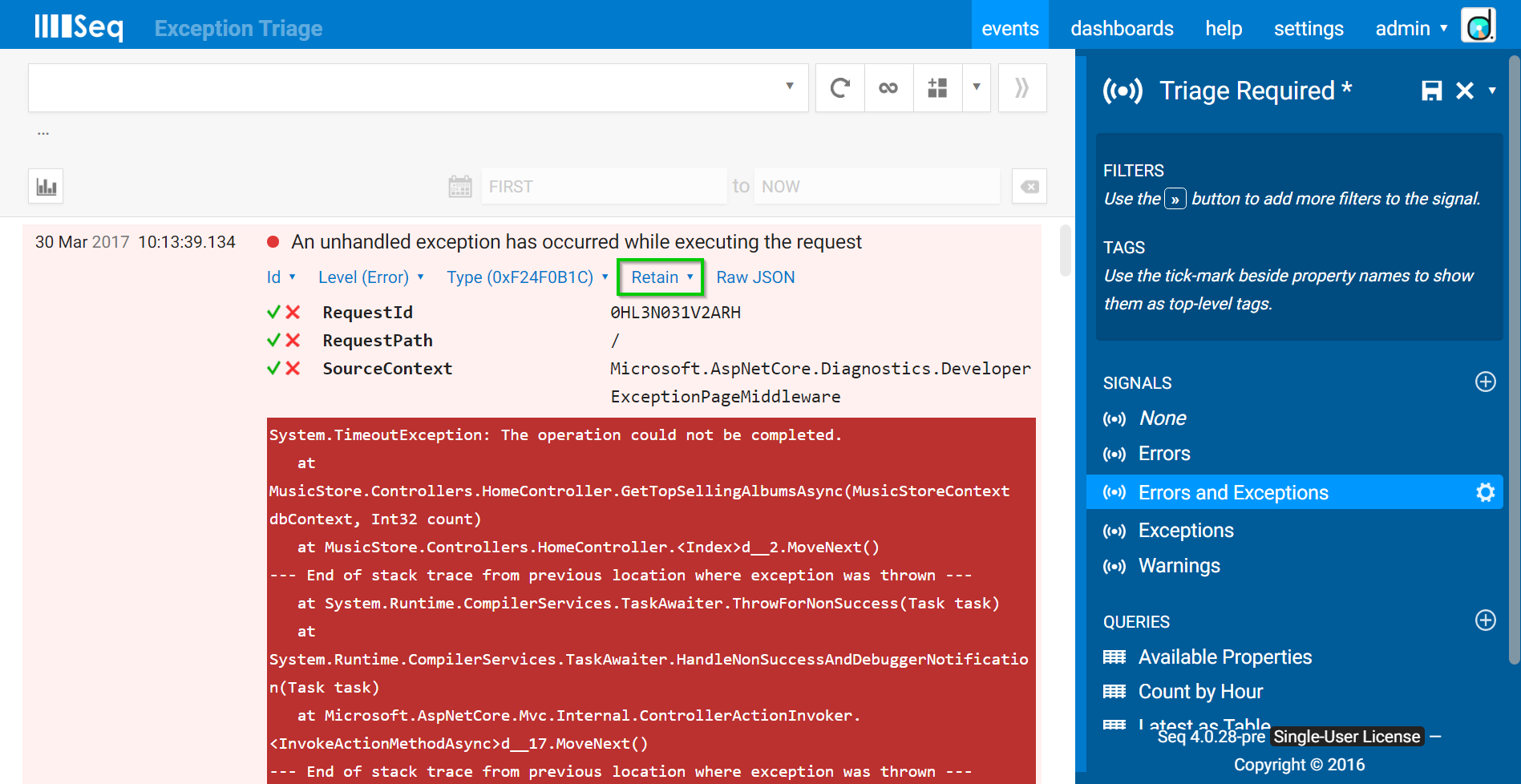
Your task is to decide whether a bug needs to be raised, or whether the exception can be ignored. If you’re raising a bug, don’t forget to use the Pin or Retain menu (highlighted in the screenshot) to make a permalink to the event that you can include in a bug report.
Once you’ve made your decision on the importance of the event, you must exclude it so that it no longer appears in the Triage Required signal. All of the contextual information we talked about in step 1 is relevant here: you need to design a filter that will exclude only the exceptions matching the one you’ve triaged.
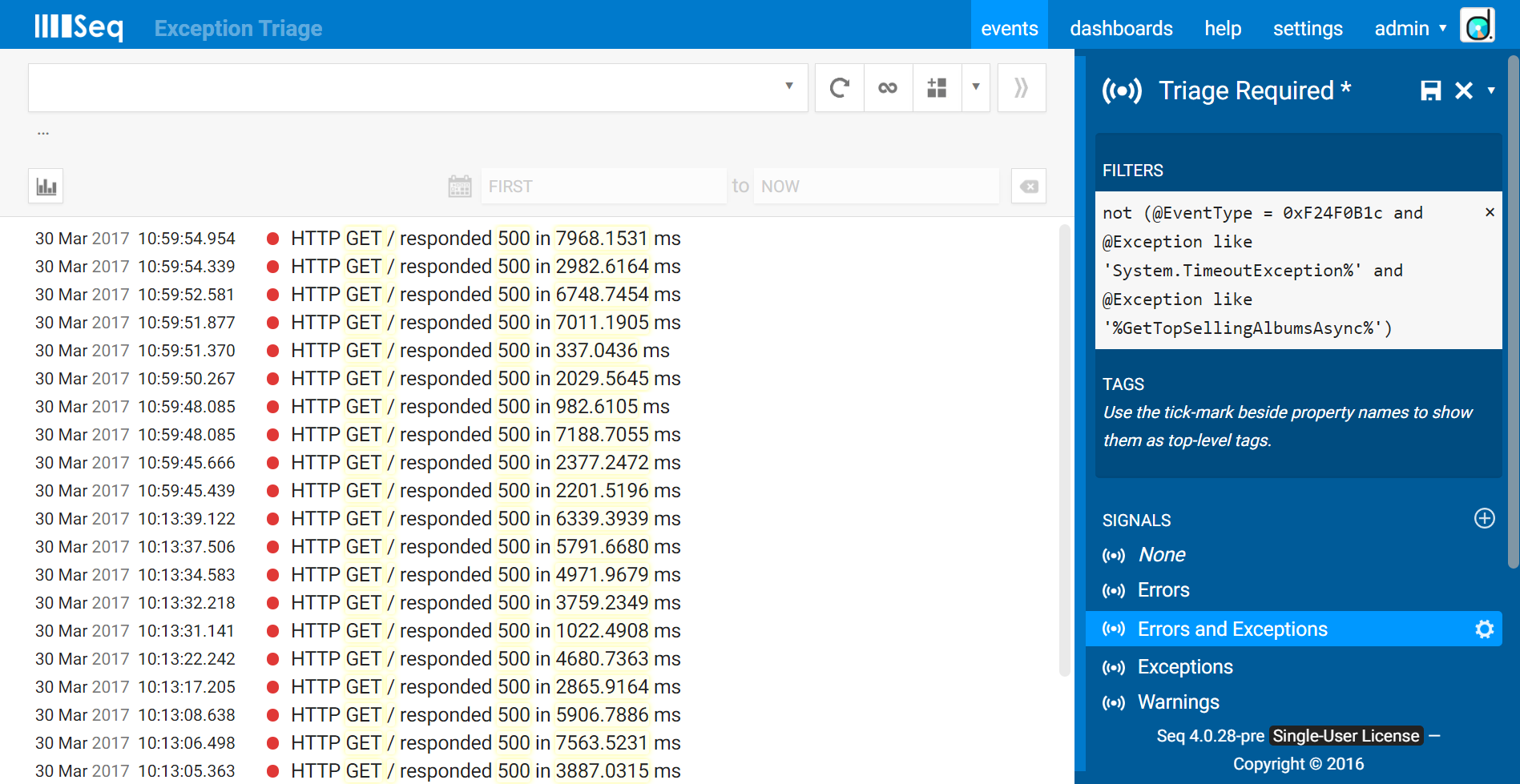
(I generally approach this by writing a filter to find only those exceptions, and then negate that filter with not as above.)
With that exception gone, you’ll now see a different exception at the top of the list. Repeat the triage process until the list is empty :-)
4. Alert and act on triage required
The combined Triage Required and Errors and Exceptions signals now present actionable errors and exceptions. You can pipe this to Slack, email, or another channel that ensures new events will get attention.
Here’s where discipline is required. When a new exception shows up in Triage Required, immediately work through step 3: decide what to do with it, and exlude it from the signal. It’s okay to choose a particular time of day to do this (say, first thing in the morning), but it has to be done dependably.
Twists and modifications
Larger teams won’t always want to maintain a single triage signal. You can divide and conquer by creating a Triage Required signal per application or per sub-team.
The great thing about this process is that you can tune it to meet your needs, and you can be as specific or as general as you like when excluding exceptions so that the most important issues are always detected, but effort kept to an acceptable level.
I’m sure this is not the only way to approach the problem, it’d be great to hear from you if you’ve found a different way to handle this effectively.