
Superpower
This post introduces a new library I’m working on called Superpower.
Text based languages, in all of their ingenious diversity, are one of the marvels of working in software. Every day we encounter multiple different languages: full-blown programming languages, serialization formats like CSV, JSON and XML, markup languages like Markdown and HTML, and others. It’s remarkable that in spite of this, the basic “working programmer’s toolkit” doesn’t include strategies for parsing text, except in the limited cases where regular expressions can be applied.
One possible explanation for this is that many parsing techniques rely on grammar definitions that must be processed separately from the code using them. The need to learn an additional grammar language, set up build-time code generation tasks, and manage (and debug) complex generated code puts up a steep barrier to adoption in many settings.
Learning about combinator-based parsing was a major discovery for me. Building parsers with straightforward code directly in C# makes processing text-based languages both accessible and practical in real-world projects.
Sprache is a project I started in late 2009 which, thanks to Mike Hadlow who revived the project and moved the codebase to GitHub, is now used in all kinds of commercial and open-source projects including EasyNetQ, Octopus Deploy, Seq, OmniXAML and JetBrains’ Rider IDE.
Sprache hits a sweet spot between simplicity and power. It’s almost embarrasingly easy to get started with, it’s capable of handling practically any real-world language, and it’s sophisticated enough to give reasonable diagnostic messages when input can’t be parsed. If you have some text to parse in .NET today, Sprache is almost certainly the quickest way to get started.
A lot of what’s great about Sprache is derived from it being a character-driven parser. Instead of dealing with separate tokenization and parsing phases, Sprache maps directly from the raw input to the final parsed result in a single step. This is a good thing because there’s only one definition of the parsing process to worry about, the concept count is kept to a minimum, and tricky ambiguities that sometimes show up in tokenizers don’t have to be dealt with.
The downside of being character-driven is that in complex parsers, it’s challenging to produce error messages that are meaningful and instructive to an end-user. The original goals of Sprache didn’t include great error messsages, and while carefully-constructed parsers can still provide reasonable messages, the intricacies of achieving them make parsers more complex and brittle than naively-written ones.
The fundamental problem is that Sprache “sees” input one character at a time, so in failing to parse:
Name ljke 'Nic%'
Sprache knows only that it found the letter j where i was expected in the keyword like:
Syntax error (col 7): unexpected `j`, expected `i`.
This is fine in a development setting, and for small inputs like the one above. In longer inputs, scanning for the mistyped j without any idea of the surrounding context, isn’t a great user experience. A parser looking at the input stream one token at a time could report:
Syntax error (col 7): unexpected identifier `ljke`.
Notice not only the whole mistyped word is shown, but that the parser knows what kind of token the word is - in this case it’s interpreted as an identifier, but errors can just as easily categorize numbers, strings, keywords and so-on.
The product I work on day-to-day is a structured log server called Seq that collects application logs and makes them queryable through a web interface. Log searches in Seq use free text and simple filter expressions such as Username = 'nblumhardt'. The filter parser, built with Sprache, is a pretty good use case for it.
Seq supports aggregations including count(), distinct(), percentile() and so on, as well as time-slicing and charting, through a SQL dialect that’s quite a bit more sophisticated. The SQL parser was built after the filter expression parser, also with Sprache, re-using most of the filter expression parser. Because the inputs are larger and more complex, the SQL parser is pushing the limits of Sprache’s character-at-a-time parsing and error reporting capabilities.
After shipping the most recent 3.3 release I decided to take a few days to see if I could improve error messages from the SQL parser. The outcome was the birth of a new open source project that’s complementary to Sprache, called Superpower.

Parser combinators
Before taking a look at Superpower, a quick recap of how combinator-based parsing works.
A parser in this model is a function that takes some input and returns a result carrying the parsed value and the remaining un-parsed input. The combinator library - in this case Superpower - defines the signature for parsers:
public delegate Result<T> TextParser<T>(TextSpan input);
Alongside various pre-built parsers like Character.Letter, “combinator” functions like AtLeastOnce() and Select() build more complex parsers out of simpler ones by functional composition.
TextParser<string> identifier = Character.Letter
.AtLeastOnce()
.Select(chars => new string(chars));
Character.Letter is a parser, and the results of applying AtLeastOnce() and Select() are also parsers: identifier is itself just a function that takes input and returns a parsed result. This ability to apply combinators to the results of other combinators makes the technique scale smoothly from handling very simple up to very complex languages.
A parser like identifier, when applied to some input, will match as much text as possible:
var result = identifier.Parse("[email protected]");
Console.WriteLine(result.Value);
// -> nblumhardt
(The Parse() method is a handy extension method that invokes a parser - we could also have written identifier(new TextSpan("..."))).)
The article Building an External DSL in C# introduces combinator-based parsing with Sprache. Because Superpower is designed primarily as an alternative for parsers that have outgrown Sprache, the rest of this post assumes you’ve read the introduction or have some familiarity with Sprache already.
What is tokenization?
The fundamental difference between how Sprache is organized, and how Superpower works, is that Superpower supports tokenization. To illustrate the process let’s take the following SQL statement as our test input. We’ll use it as the basis for demonstrating a complete (though simple) parser built with Superpower:
select 1 + 23
This is a just a computation of the single value 24 - but parsing it will be enough to keep us busy :-).
The end result produced by the example will be a tree structure describing the query. We won’t consider the full syntax tree, but focus only on parsing the input into the few nodes that are needed to represent the specific expression above.
Before trying to assemble the expression tree, the job of a tokenizer is to split the input string select 1 + 23 into a list of tokens, discarding irrelevant whitespace.
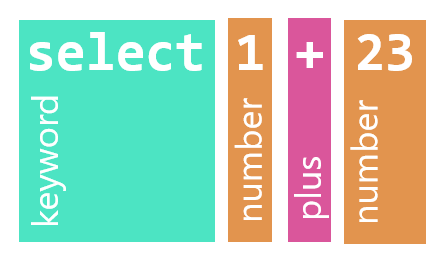
Each token identifies a span of text (the lexeme) tagged with the token’s kind: keyword, number, etc. Tokenization can be as simple as a string.Split(), but tokenizers are usually a bit more sophisticated:
- Assigning a rich vocabulary of kinds to the tokens makes the subsequent parsing stage simpler and faster,
- Grammars that include
"string literals"need to preserve the whitespace within each literal, - Grammars that support
/* comments */often strip out the comments as though they are whitespace, and - In the case of Superpower, the spans are represented efficiently as slices of the source text, rather than individually-allocated strings.
In the diagram above, you can see how the input is broken into several kinds of tokens: the keyword select, number tokens 1 and 23, and the + operator.
Writing a tokenizer
Before going too far into the API of the new library, I should point out that Superpower is still evolving. There are some rough edges, and still a lot of improvements to make in how things fit together (if you can help, or have suggestions, it’d be great to hear from you). As the library evolves, I plan to update this post so that everything stays in sync.
If you want to follow along, now is a good time to grab a copy of the complete example from this GitHub repository or if you’re feeling a little more adventurous:
Install-Package Superpower -Pre
In the statement select 1 + 23 we have three kinds of tokens, which we’ll represent using an enum:
enum SqlToken
{
None,
Keyword,
Number,
Plus
}
(Every C# enum should have a None/Empty/Undefined member with value 0, since that’s the value an uninitialized instance of the type will get by default. Assigning a sentinel value to the 0 member makes it easier to detect bugs caused by forgetting to assign a value.)
Tokenizers in Superpower are subclasses of Tokenizer<TKind>. Using an abstract base class instead of a more functional approach has the advantage of being a bit more discoverable and prescriptive.
class SqlTokenizer : Tokenizer<SqlToken>
{
}
The splitting of the input into discrete tokens is done in the Tokenize() method:
protected override IEnumerable<Result<SqlToken>> Tokenize(TextSpan input)
{
var next = SkipWhiteSpace(input);
if (!next.HasValue)
yield break;
do
{
if (char.IsLetter(next.Value))
{
var keywordStart = next.Location;
do
{
next = next.Remainder.ConsumeChar();
} while (next.HasValue && char.IsLetter(next.Value));
yield return Result.Value(SqlToken.Keyword, keywordStart, next.Location);
}
else if (char.IsDigit(next.Value))
{
var integer = Numerics.Integer(next.Location);
yield return Result.Value(SqlToken.Number, next.Location, integer.Remainder);
next = integer.Remainder.ConsumeChar();
}
else if (next.Value == '+')
{
yield return Result.Value(SqlToken.Plus, next.Location, next.Remainder);
next = next.Remainder.ConsumeChar();
}
else
{
yield return Result.Empty<SqlToken>(next.Location, $"unrecognized `{next.Value}`");
next = next.Remainder.ConsumeChar(); // Skip the character anyway
}
next = SkipWhiteSpace(next.Location);
} while (next.HasValue);
}
The first thing to notice is that the tokenizer is imperative - it’s not declarative magic like the combinator-based parsers that will eventually consume the tokens. While a little bit of sugar is supported (we’ll walk through the code block-by-block shortly), tokenizers are meant to be simple, efficient, low-level things.
To test the tokenizer on our input I’m using this little snippet:
var tokenizer = new SqlTokenizer();
var tokens = tokenizer.Tokenize("select 1 + 23");
foreach (var token in tokens)
{
Console.WriteLine(token);
}
Which produces:
Keyword@0 (line 1, column 1): select
Number@7 (line 1, column 8): 1
Plus@9 (line 1, column 10): +
Number@11 (line 1, column 12): 23
Success! Here’s the low-down.
protected override IEnumerable<Result<SqlToken>> Tokenize(TextSpan input)
{
Tokenize() is called with a TextSpan. This is one of Superpower’s core types - it is a struct carrying the source string, a position from which the span starts (0 at the beginning of the string), and the length of the span. Using spans instead of strings cuts out allocations, and since practically all text referred to during parsing is within the same string object there’s less chasing around memory following pointers to small strings.
var next = SkipWhiteSpace(input);
if (!next.HasValue)
yield break;
The tokenizer works character-by-character. The SkipWhiteSpace() method provided on the base Tokenizer class returns Result<char>, a struct that either holds a char value or an error message describing why no value could be returned. Once next.HasValue returns false, we’re at the end of the input.
do
{
if (char.IsLetter(next.Value))
{
var keywordStart = next.Location;
do
{
next = next.Remainder.ConsumeChar();
} while (next.HasValue && char.IsLetter(next.Value));
yield return Result.Value(SqlToken.Keyword, keywordStart, next.Location);
}
The main tokenization loop begins by checking for a letter, assuming for now that anything beginning with a letter is a keyword. If a letter is found, it advances until no further letters are found, and returns a result carrying the kind SqlToken.Keyword that identifies the span beginning with keywordStart through to the beginning of the next un-parsed location in the input string.
else if (char.IsDigit(next.Value))
{
var integer = Numerics.Integer(next.Location);
yield return Result.Value(SqlToken.Number, next.Location, integer.Remainder);
next = integer.Remainder.ConsumeChar();
}
Here’s the little nicety I alluded to earlier. When a digit is encountered, we use a parser, here a pre-built one called Numerics.Integer, to match the input. Numerics.Integer is a character parser just like the ones implemented in Sprache. This means that if you’re migrating a Sprache parser to Superpower, individual parsers can be re-used as recognizers in a Superpower tokenizer. This is an interesting scenario to explore further - I’m keen to figure out whether a basic tokenizer can be implemented simply by providing an ordered-list of character parsers. For now, this feature has made porting the hundreds of lines of SQL parsing code in Seq across to Superpower much easier than it would have been to start from scratch.
else if (next.Value == '+')
{
yield return Result.Value(SqlToken.Plus, next.Location, next.Remainder);
next = next.Remainder.ConsumeChar();
}
The simplest case is when a + is encountered. Easy!
else
{
yield return Result.Empty<SqlToken>(next.Location, $"unrecognized `{next.Value}`");
next = next.Remainder.ConsumeChar(); // Skip the character anyway
}
Error reporting in this tokenizer is rudimentary - in a better tokenizer we’d grab the rest of the unrecognized token and include it in the error message, not just the first character. Instead of bailing out immediately like this, it’s also viable to return the unrecognized input as a token of a kind not used by the parser (e.g. SqlToken.Error) so that errors can be reported later on in the context of the tokens that the parser expects.
next = SkipWhiteSpace(next.Location);
} while (next.HasValue);
Between tokens we use SkipWhiteSpace() again to move next to the position of the first non-whitespace character.
Deciding what constitutes a token kind
It’s quite tricky to decide what should constitute a token. Should select be a Keyword, or should we have created SqlToken.Select instead? What about + - would SqlToken.Operator have been a better choice?
On this question I turned to the Roslyn codebase to see what’s done over there. The approach taken by Roslyn’s C# compiler appears to be to make the tokens precise and specific.
By that measure, select is better represented as SqlToken.Select - and trying this approach seems to confirm it’s the way to go. I used Keyword in the example because it provides a good illustration of how to walk through the character stream in the tokenizer, as you might for an Identifier token.
Writing a parser
After tokenization, the goal of parsing is usually to construct a representation of the input that’s convenient for a program to work with. In this case, it’s an object model representing an abstract syntax tree:
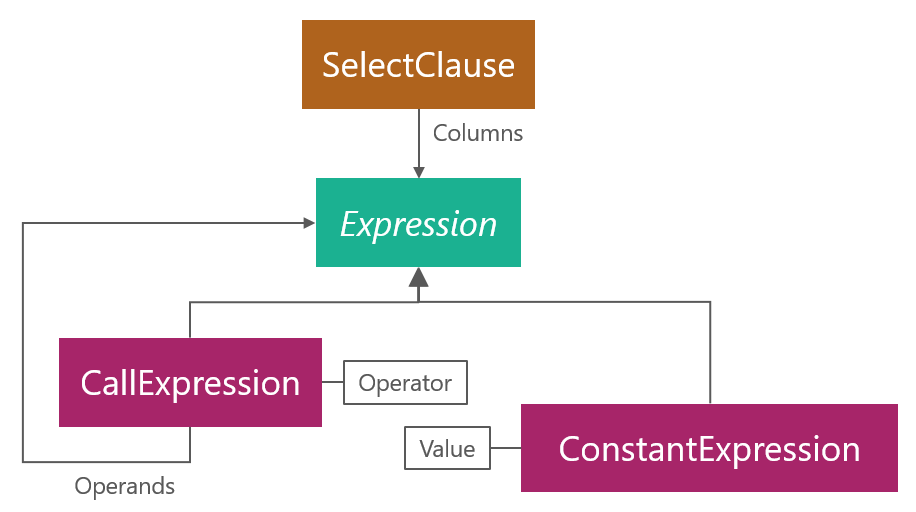
I’ve chosen to represent binary addition nodes as n-ary CallExpressions instead of as the usual UnaryExpression, BinaryExpression and so-on because once the input is parsed we don’t really care if an expression takes one, two or n operands, only that there are some operands to combine and an operation like add to apply.
The boxes above correspond to the following C# classes:
class SelectClause
{
public Expression[] Columns { get; set; }
public SelectClause(Expression[] columns)
{
Columns = columns;
}
}
abstract class Expression
{
}
class CallExpression
{
public string Operator { get; set; }
public Expression[] Operands { get; set; }
public CallExpression(string @operator, params Expression[] operands)
{
Operator = @operator;
Operands = operands;
}
}
class ConstantExpression : Expression
{
public int Value { get; set; }
public ConstantExpression(int value)
{
Value = value;
}
}
As the parser encounters tokens in the input it builds up the syntax tree by creating instances of these classes:
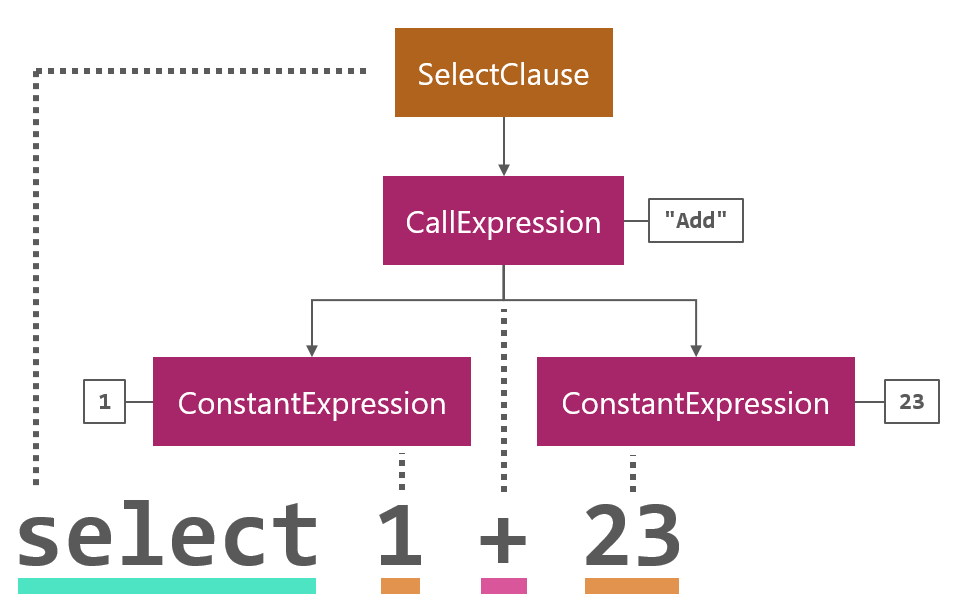
This is a bit trickier to visualize than tokenization is, but this is also where Superpower does the bulk of the work.
Numbers
The best place to start in any combinator-driven parser is at the leaves of the desired syntax tree. In our example this means starting at the parser that creates ConstantExpression nodes out of Number tokens:
static class SqlParser
{
public static TokenListParser<SqlToken, Expression> Constant =
Token.EqualTo(SqlToken.Number)
.Apply(Numerics.IntegerInt32)
.Select(n => (Expression) new ConstantExpression(n));
}
The parser is a TokenListParser<SqlToken, Expression>. The generic arguments identify the kinds of tokens in the input, and the kind of value that the parser produces. In this case the result type is the abstract class Expression, and the result itself is an instance of ConstantExpression. (The cast in the last line is necessary because parsers in Superpower don’t yet deal with covariant result types.)
The input to the parser is the token list produced by the tokenizer. The parser is a public field in this example so that it’s easy to exercise independently:
var tokens = tokenizer.Tokenize("23");
var twentyThree = SqlParser.Constant.Parse(tokens);
Console.WriteLine(twentyThreeExpr);
The value twentyThree is a ConstantExpression. I’ve overridden ToString() in the various syntax tree classes so that they can be printed to the console; we get:
ConstantExpression { Value = 23 }
Let’s have a look at how the parser is constructed, line by line.
Token.EqualTo(SqlToken.Number)
The first step in parsing a constant at the head of the list of SQL tokens is to match a single token of the kind SqlToken.Number. Makes sense :-).
.Apply(Numerics.IntegerInt32)
Here’s another place where the token-based and character-based facilities of Superpower overlap. Apply() accepts a Parser<T> and applies it to the value of the token. So, the result of this step will be the result of applying Numerics.IntegerInt32 (a handy built-in parser) to the span of text "1" or "23" to get the corresponding int values 1 or 23.
.Select(n => (Expression) new ConstantExpression(n));
With the numeric value in hand, Select() constructs the final resulting ConstantExpression.
Operator calls
Now that we can parse numeric constants, we can start working our way up the tree to the more interesting productions. Here is one way to approach operator calls like 1 + 23:
public static TokenListParser<SqlToken, Expression> Call =
from lhs in Constant
from plus in Token.EqualTo(SqlToken.Plus)
from rhs in Constant
select (Expression) new CallExpression("Add", lhs, rhs);
The LINQ query comprension specifies a sequence of parsers: first the left-hand-side Constant, then the plus token, then the right-hand Constant. It’s simple to read, but not really what we intended. How about 1 + 23 + 456? In the more complex expression, the call 1 + 23 is the left-hand operand of a second CallExpression with 456 on the right-hand side.
Parsing nested expression trees is so common that support is built into Superpower:
public static TokenListParser<SqlToken, Expression> Call =
Parse.Chain(
Token.EqualTo(SqlToken.Plus),
Constant,
(op, lhs, rhs) => new CallExpression("Add", lhs, rhs));
Instead of sequencing the first operand, operator and second operand, another helper function Parse.Chain() is used. This function takes a parser that recognizes operators, a second parser that recognizes operands, and finally a function that combines operands into syntax tree nodes. Chain() avoids the creation of left-recursive parsers, which you’ll have to take on faith at this point as a good thing.
Select
The last step in our goal of parsing select 1 + 23 is to handle the structure of the overall SelectClause.
public static TokenListParser<SqlToken, Expression> Expression = Call;
public static TokenListParser<SqlToken, SelectClause> SelectClause =
from keyword in Token.EqualToValue(SqlToken.Keyword, "select")
from columns in Expression.ManyDelimitedBy(Token.EqualTo(SqlToken.Comma))
select new SelectClause(columns);
The alias Expression that is just another name for Call makes the second parser easier to read.
SelectClause first recognizes the select keyword:
from keyword in Token.EqualToValue(SqlToken.Keyword, "select")
EqualToValue() matches both the kind and value of the token. As mentioned a little earlier, introducing and matching on a more specific SqlToken.Select would also be appropriate here.
from columns in Expression.ManyDelimitedBy(Token.EqualTo(SqlToken.Comma))
ManyDelimitedBy() matches many instances of Expression with comma tokens in between them. The tokenizer shown earlier doesn’t include Comma, but you can add it in exactly the same way as Plus is tokenized.
Running SqlParser.SelectClause on our input string select 1 + 23 produces:
SelectClause {
Columns = [
CallExpression {
Operator = "Add",
Operands = [
ConstantExpression { Value = 1 },
ConstantExpression { Value = 23 }
]
}
]
}
And, that’s just about it! This fairly trivial example has taken us through the basics of parsing token lists with Superpower. There are some examples and tests spread througout the source code repository that will help fill in some gaps if you’re interested to learn more.
Status
I’d initially planned to write quite a bit more about the design of Superpower, but I’m afraid that this introduction is already stretching what can be comfortably read in a single blog post, so I’ll wrap up now with a quick note on the status of the project.
While the goals of the project include great error messages, respectable performance, and a clean migration path from Sprache, the codebase is still evolving and might not yet meet these goals in every case. If you have an existing parser that’s pushing the limits of error reporting with Sprache, you’re probably familiar enough with the territory to roll your sleeves up and make it work with Superpower.
If you’re keen to learn more about combinator-based parsing in C# or have a small parser to implement today, Sprache is almost certainly a better place to start. Learning how combinator-based parsing works is enough of a challenge, without concurrently tracking a new and fast-moving codebase. Once the dust has settled, if you find your problem fits the token-driven approach better, most of what you learn will apply to both libraries.
I’m looking forward to writing a bit more about Superpower as the project takes shape, and I hope I’ll even pick up a few things that I can take back and use to improve Sprache, which I also expect to keep using on a daily basis.
If you have a chance to check out either project it’d be cool to hear from you. Happy parsing! ;-)