
Message templates and properties – structured logging concepts in .NET (3)
This post is the third in a series; start here.
Trojan eventing
A long time ago I encountered a library called Bamboo.Prevalence, by the amazing Rodrigo “Bamboo” de Oliveira. Following Java’s Prevayler, the idea underpinning object prevalence is that rather than persisting your application’s object model as a point-in-time snapshot, a log of commands affecting the model (Add item 5 to order 1!) is written instead. Later, to recreate the model at a point in time, the application can just replay those commands from the beginning to arrive at the desired state.
I was fascinated by the idea of object prevalence. It turned the whole notion of application state from a static, opaque thing into a dynamic and detailed view of the application’s history.
Prevalence never really took off in .NET because of the practical challenges associated with data migration, reporting, integration points and so-on. Existing infrastructure expected a SQL database, and moving away from that model would have necessitated “rewriting the world”.
Still, a little later on I encountered this idea again in the guise of event sourcing, an architectural pattern based on a similar application-state-as-transaction-log model.
As with object prevalence before, I found event sourcing very interesting, but as with object prevalence again, the divide between the architecture and the status quo in typical enterprise software environments kept it out of most projects I was involved with.
Events are exciting because they capture a whole dimension that’s otherwise invisible, but equally if not more important than the static view that the current system state describes. In .NET, messaging architectures sometimes capture an event-oriented view of an application, and Reactive Extensions (Rx) has had some success with getting a first class treatment of events into .NET apps, but events are still usually a secondary, transient consideration and hence a lost opportunity for diagnostics and analysis.
Eventually, down the line, I stumbled across what you might call Trojan eventing, a sneaky way of grafting a fully-structured, persistent, queryable event stream onto an application, without a change of architecture and in most cases, without many of your teammates even noticing! Hey, your app right now might be producing a first-class event stream! To help you recognize it, this post describes what it looks like ;-)
Capturing vs. formatting log event data
The classic workflow associated with text logging goes something like this:
-
Take the description of an event and associated parameters
-
Format it into human-readable text
-
Collect the text
-
Parse the text to recover individual parameter values
-
Filter based on parameters
-
View matching events
If you break this down, the formatting step (2) actually achieves two things. The event is made into something human readable (the formatting part), but by serializing the whole thing as text, the associated parameters are also being captured in a form that can survive outside the application.
Step 4, where we need to expend effort to recover information from the event for machine processing, comes about because we threw all of the structural information away at step 2. This is painful because practically every interesting thing we can do with a log event revolves around the specific parameter values associated with the event. Writing regular expressions to extract those values gets tiring quickly.
To fix this, structured logging approaches data capture and formatting separately. In the structured logging workflow, capturing happens first while formatting an event into human-readable text is deferred until it’s needed later on, after any property-based filtering has been applied:
-
Take the description of an event and associated parameters
-
Capture the description and parameter values
-
Collect a serialized representation like JSON
-
Filter based on parameters
-
Format into human-readable text*
-
View matching events
*Formatting can be deferred, but it doesn’t necessarily have to be – the collected JSON can include the human-readable representation alongside the template and parameters, if it makes processing easier in subsequent steps.
What this all amounts to is that the log statements already in your application:
Log.Information("Checked out order {0} for ${1:C}", order.Id, order.Total);
// -> Checked out order o12345 for $15.30
Can be converted into fully-structured, first-class events with almost insignificant effort:
Log.Information("Checked out order {OrderId} for ${Total:C}", order.Id, order.Total);
// -> Checked out order o12345 for $15.30
// -> { … "OrderId": "o12345", "Total":"15.3" … }
The message template "Checked out order {OrderId} for ${Total:C}" names the parameters of the log event (and in some cases describes how they are captured) so that they can be represented as properties in a structured format like JSON, and easily manipulated without the need for free-text parsing.
Message template basics
Message templates are a superset of .NET format strings. That means every valid .NET format string is also a valid message template.
Log.Information("Checked out order {0} for ${1:C}", order.Id, order.Total);
The property names captured in the example above will be 0 and 1.
While numeric property names are a useful compatibility feature when moving code from a format-based logging implementation like log4net, descriptive names are much more pleasant to work with. Message templates extend format strings by allowing textual names to be used instead of numeric placeholders.
In a message template with named placeholders, the parameters specified alongside the template are always matched from left to right, that is, the two properties First and Second will have the values 1 and 2:
Log.Information("Capturing {First} and {Second}", 1, 2);
When writing a message template, either numeric or named placeholders must be used. While libraries like Serilog will try to do something reasonable when confronted with a mix of named and numeric placeholders, doing so doesn’t make much sense.
This is because when capturing, named placeholders are matched strictly left-to-right with the arguments, while numeric placeholders in .NET format strings allow out-of-order capturing and repeated substitutions of the same index.
Because of their relationship to standard .NET format strings, width and format specifiers are also supported in message templates.
Log.Information("Capturing {First,8} and {Second:x8}", 1, 2);
// -> Capturing 1 and 00000002
(To fully support deferred rendering, both the raw property value and its formatted representation need to be captured up front in this scenario.)
Likewise, braces in the message itself can be escaped by \{\{ doubling them.
Validating message template usage
SerilogAnalyzer is a Roslyn-based Visual Studio plug-in by Robin Sue that validates message template syntax and checks binding to parameters.
Usage issues result in a red squiggly, and an error or warning in the Visual Studio error list.
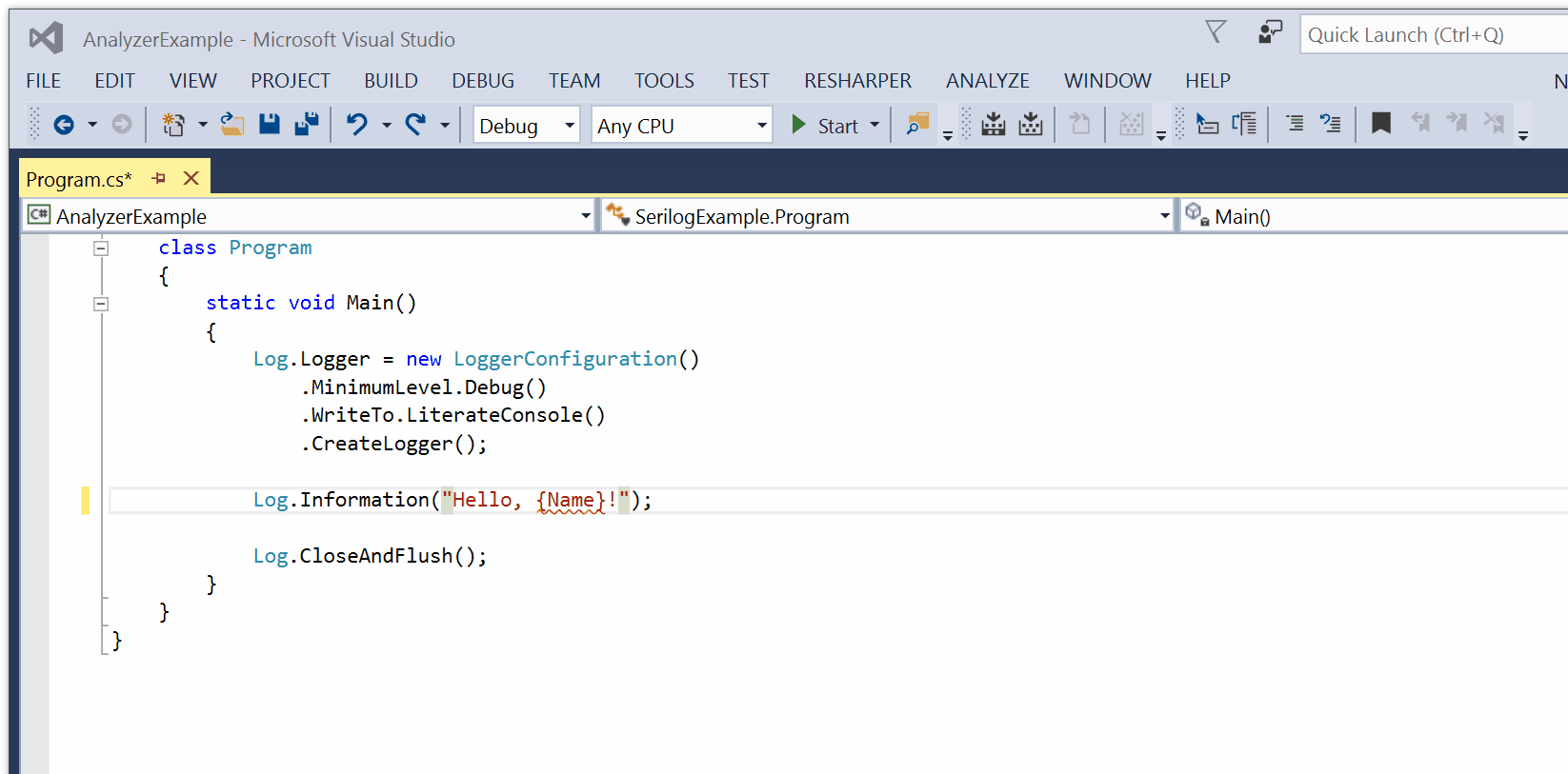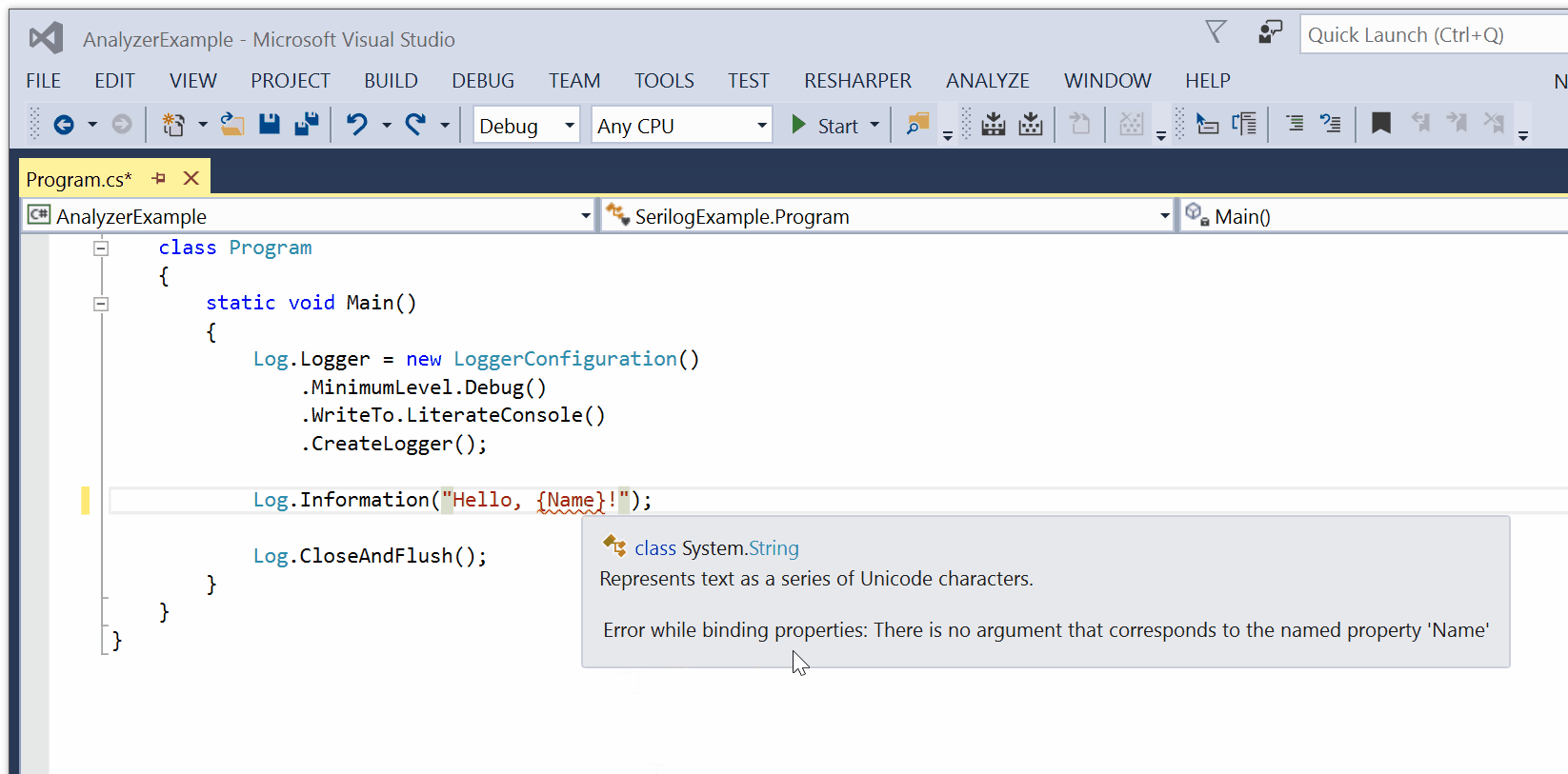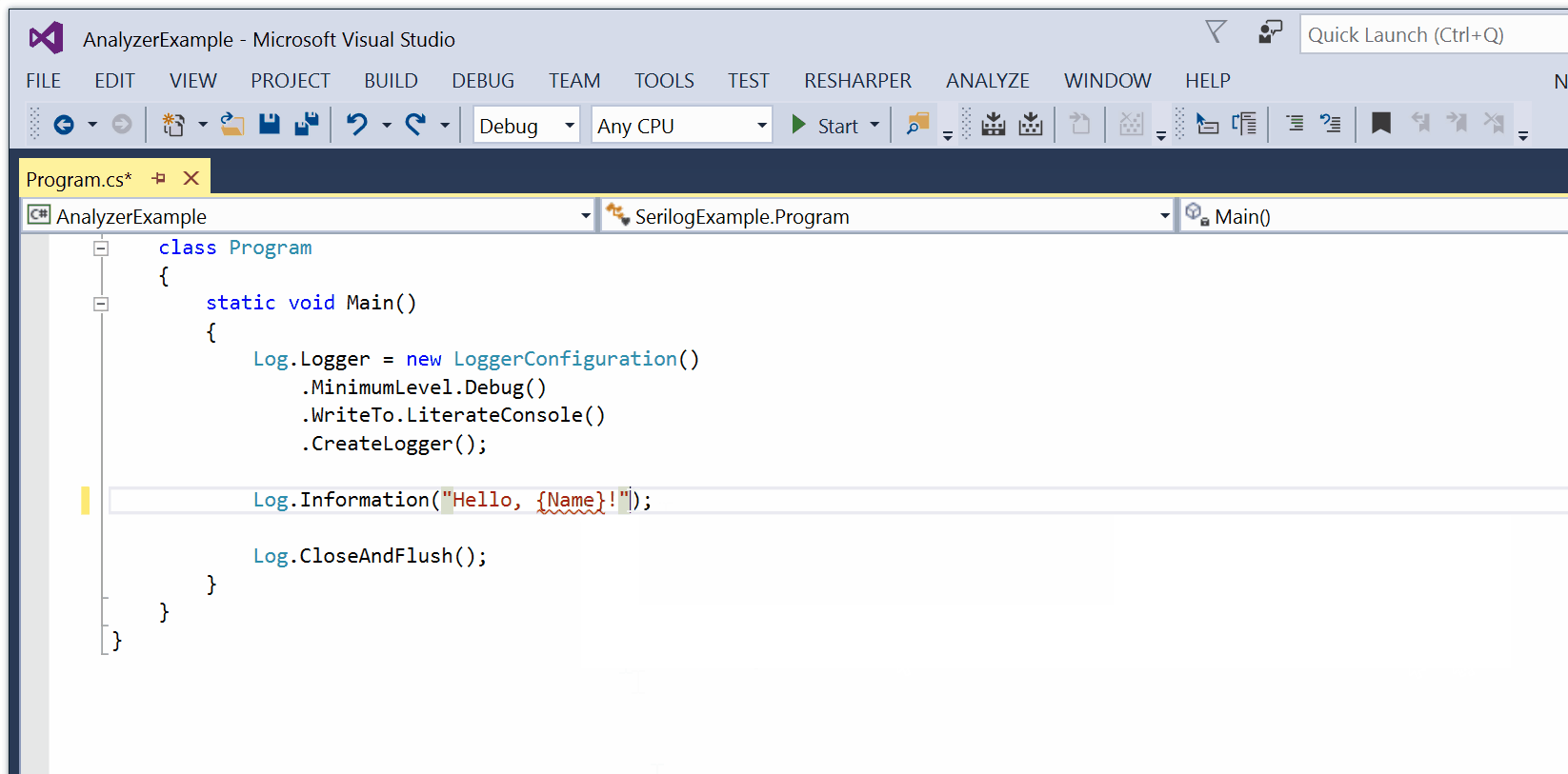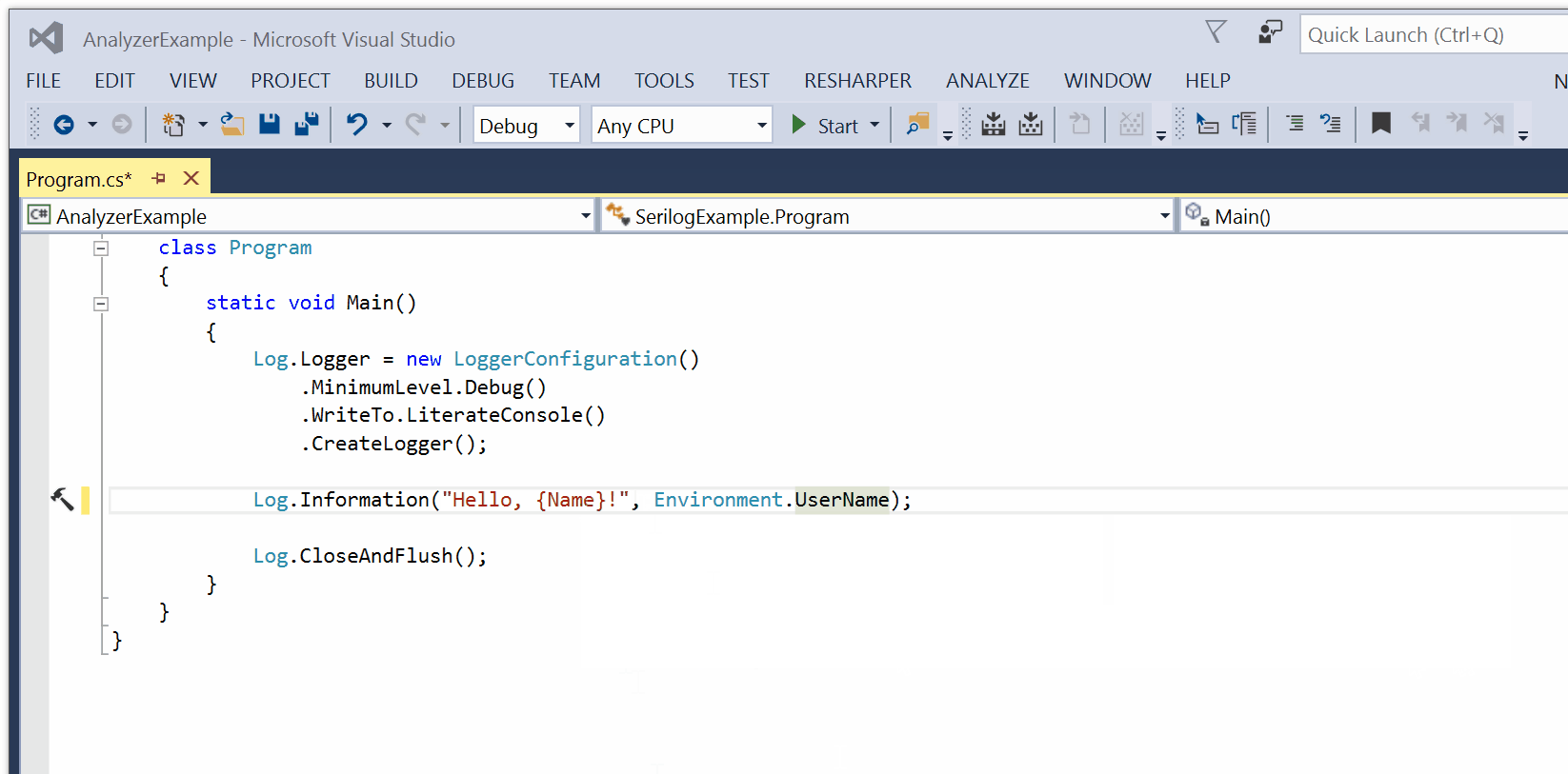
You can download and install the Serilog Analyzer VSIX package from the GitHub project page.
Capturing structure
The other extension that message templates add to typical format strings is control for how parameters are captured.
By default, a parameter logged alongside a message template will be converted into a simple scalar value like string or int. This matches our intuition for how format strings are supposed to work: if you provide a complex object, say, a BlogPost instance, it’ll be logged via its ToString() representation:
var post = new BlogPost("Structured Logging Concepts")
{
Tags = { "logging", "diagnostics", "analytics" }
};
Log.Information("Publishing {Post}", post);
// -> Publishing Structured Logging Concepts
This is a very limiting: later when searching the log, it would be useful to be able to find, say, all published posts that are tagged “diagnostics”.
By prefixing an @ sigil ahead of the property name, the post object will be captured in a structured representation instead.
Log.Information("Publishing {@Post}", post);
// -> Publishing BlogPost { Name: "Structured Logging Concepts", Tags: "logging", … }
If the destination format is JSON, Post will be serialized as an object with detailed Name and Tag properties. (Serializing logger – so now you know ;-) )
Up next…
We’ll see how complex data is captured in more detail in the upcoming post on serialization. Up next we’ll consider event types, the final detail necessary before we can call the discussion of message templates complete.