
Aggregate Queries in Seq Part 4: Planning
Seq is a log server designed to collect structured log events from .NET apps. This month I’m working on adding support for aggregate queries and blogging my progress as a diary here. This is the fourth installment – you can catch up on Goals, Syntax, and Parsing in the first three posts.
So, this post and the next are about “planning” and “execution”. We left off a week ago having turned a query like:
select count(*)
where ApplicationName == "Admissions"
group by time(1d), ExceptionType
Into an expression tree:
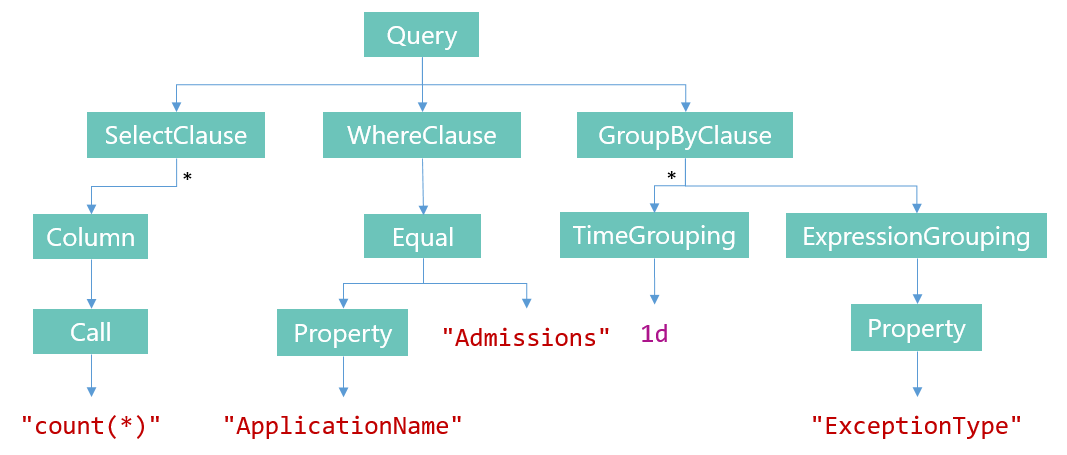
Pretty as it looks, it’s not obvious how to take a tree structure like this, run it over the event stream, and output a rowset. We’ll break the problem into two parts – creating an execution plan, then running it. The first task is the topic of this post.
Planning
In a relational database, “planning” is the process of taking a query and converting it into internal data structures that describe a series of executable operations to perform against the tables and indexes, eventually producing a result. The hard parts, if you were to implement one, seem mostly to revolve around choosing an optimal plan given heuristics that estimate the cost of each step.
Things are much simpler in Seq’s data model, where there’s just a single stream of events indexed by (timestamp, arrival order), and given the absence of joins in our query language so far. The goal of planning our aggregate queries is pretty much the same, but the target data structures (the “plans”) only need to describe a small set of pre-baked execution strategies. Here they are.
Simple projections
Let’s take just about the simplest query the engine will support:
select MachineName, ThreadId
This query isn’t an aggregation at all: it doesn’t have any aggregate operators in the list of columns, so the whole rowset can be computed by running along the event stream and plucking out the two values from each event. We’ll refer to this as the “simple projection” plan.
A simple projection plan is little more than a filter (in the case that there’s a where clause present) and a list of (expression, label) pairs representing the columns. In Seq this looks much like:
class SimpleProjectionPlan : QueryPlan
{
public FilterExecutionPlan Filter { get; }
public ProjectedColumn[] Columns { get; }
public SimpleProjectionPlan(
ProjectedColumn[] columns,
FilterExecutionPlan filter = null)
{
if (columns == null) throw new ArgumentNullException(nameof(columns));
Columns = columns;
Filter = filter;
}
}
We won’t concern ourselves much with FilterExecutionPlan right now; it’s shared with Seq’s current filter-based queries and holds things like the range in the event stream to search, a predicate expression, and some information allowing events to be efficiently skipped if the filter specifies any required or excluded event types.
Within the plan, expressions can be stored in their compiled forms. Compilation can’t be done any earlier because of the ambiguity posed by a construct like max(Items): syntactically this could be either an aggregate operator or a scalar function call (like length(Items) would be). Once the planner has decided what the call represents, it can be converted into the right representation. Expression compilation is another piece of the existing Seq filtering infrastructure that can be conveniently reused.
Aggregations
Stepping up the level of complexity one notch:
select distinct(MachineName) group by Environment
Now we’re firmly into aggregation territory. There are two parts to an aggregate query – the aggregates to compute, like distinct(MachineName), and the groupings over which the aggregates are computed, like Environment. If there’s no grouping specified, then a single group containing all events is implied.
class AggregationPlan : QueryPlan
{
public FilterExecutionPlan Filter { get; }
public AggregatedColumn[] Columns { get; }
public GroupingInstruction[] Groupings { get; set; }
public AggregationPlan(
AggregatedColumn[] columns,
GroupingInstruction[] groupings,
FilterExecutionPlan filter = null)
{
if (columns == null) throw new ArgumentNullException(nameof(columns));
if (groupings == null) throw new ArgumentNullException(nameof(groupings));
Filter = filter;
Columns = columns;
Groupings = groupings;
}
}
This kind of plan can be implemented (naiively perhaps, but that’s fine for a first-cut implementation) by using the groupings to create “buckets” for each group, and in each bucket keeping the intermediate state for the required aggregates until a final result can be produced.
Aggregated columns, in addition to the expression and a label, carry what’s effectively the constructor parameters for creating the bucket to compute the aggregate. This isn’t immediately obvious based on the example of distinct, but given another example the purpose of this becomes clearer:
percentile(Elapsed, 95)
This expression is an aggregation producing the 95th percentile for the Elapsed property. An AggregatedColumn representing this computation has to carry the name of the aggregate ("percentile") and the argument 95.
Time slicing
Finally, the example we began with:
select count(*)
where ApplicationName == "Admissions"
group by time(1d), ExceptionType
Planning this thing out reveals a subtlety around time slices in queries. You’ll note that the time(1d) group is in the first (dominant) position among the grouped columns. It turns out the kind of plan we need is completely different depending on the position of the time grouping.
In the time-dominant example here, the query first breaks the stream up into time slices, then computes an aggregate on each group. Let’s refer to this as the “time slicing plan”.
class TimeSlicingPlan : QueryPlan
{
public TimeSpan Interval { get; }
public AggregationPlan Aggregation { get; }
public TimeSlicingPlan(
TimeSpan interval,
AggregationPlan aggregation)
{
if (aggregation == null) throw new ArgumentNullException(nameof(aggregation));
Interval = interval;
Aggregation = aggregation;
}
}
The plan is straightforward – there’s an interval over which the time groupings will be created, and an aggregation plan to run on the result.
The output from this query will be a single time series at one-day resolution, where each element in the series is a rowset containing (exception type, count) pairs for that day.
The alternative formulation, where time is specified last, would produce a completely different result.
select count(*)
where ApplicationName == "Admissions"
group by ExceptionType, time(1d)
The output of this query would be a result set where each element contains an exception type and a timeseries with counts of that exception type each day. We’ll refer to this as the “timeseries plan”.
Both data sets contain the same information, but the first form is more efficient when exploring sparse data, while the second is more efficient for retrieving a limited set of timeseries for graphing or analytics.
To keep things simple (this month!) I’m not going to tackle the timeseries formulation of this query, instead working on the time slicing one because I think this is closer to the way aggregations on time will be used in the initial log exploration scenarios that the feature is targeting.
Putting it all together
So, to recap – what’s the planning component? For our purposes, planning will take the syntax tree of a query and figure out which of the three plans above – simple projection, aggregation, or time slicing – should be used to execute it.
The planner itself is a few hundred lines of fairly uninteresting code; I’ll leave you with one of the tests for it which, like many of the tests for Seq, is heavily data-driven.
[Test]
[TestCase("select MachineName", typeof(SimpleProjectionPlan))]
[TestCase("select max(Elapsed)", typeof(AggregationPlan))]
[TestCase("select MachineName where Elapsed > 10", typeof(SimpleProjectionPlan))]
[TestCase("select StartsWith(MachineName, "m")", typeof(SimpleProjectionPlan))]
[TestCase("select max(Elapsed) group by MachineName", typeof(AggregationPlan))]
[TestCase("select percentile(Elapsed, 90) group by MachineName", typeof(AggregationPlan))]
[TestCase("select max(Elapsed) group by MachineName, Environment", typeof(AggregationPlan))]
[TestCase("select distinct(ProcessName) group by MachineName", typeof(AggregationPlan))]
[TestCase("select max(Elapsed) group by time(1s)", typeof(TimeSlicingPlan))]
[TestCase("select max(Elapsed) group by time(1s), MachineName", typeof(TimeSlicingPlan))]
[TestCase("select count(*)", typeof(AggregationPlan))]
public void QueryPlansAreDetermined(string query, Type planType)
{
var tree = QueryParser.ParseExact(query);
QueryPlan plan;
string[] errors;
Assert.IsTrue(QueryPlanner.Plan(tree, out plan, out errors));
Assert.IsInstanceOf(planType, plan);
}
Part five will look at what has to be done to turn the plan into a rowset – the last thing to do before the API can be hooked up!