
Seq 1.5 preview
TL;DR: The next point release of Seq is a bit broader in scope than what we’ve shipped in previous point releases. Storage and caching changes in Seq 1.5 bring some noticeable improvements to performance, responsiveness and manageability.
Since Seq first arrived a year ago, its storage has been a simple b-tree based data file managed by ESENT. This had pros as well as cons: on the _pro-_side, we’ve been able to keep our efforts focused on making Seq quick to set up and easy to use while ESENT does its thing keeping data safe and accessible on disk.
This approach has taken us a long way, but coupled with the particular access patterns generated by log data, it does lead us to some cons, the biggest of which we’re addressing in Seq 1.5.
Query performance and cache efficiency
In Seq 1.4, we left caching decisions to ESENT – what to cache, when to expire it, and how much RAM to use in the process. For the most part this did a fine job, but it left a couple of important opportunities on the table.
Segmented caching
Log data has a very specific access pattern: recent events are always more interesting than historical ones. A couple of queries deep into history shouldn’t cause more recent events to be purged from cache. Recently-written events should get to the cache before needing queries to “warm them up” and so-on.
In 1.5, Seq keeps a time-ordered list of cached event segments. Each segment is a time slice – the preview uses 1-day slices as the unit of granularity. As RAM fills up, segments are dropped from the end of the list, preserving more recent events.

It’s a very simple strategy, but an effective one – response times on queries improve dramatically when all data is in cache, and most queries of interest are filled by recent events.
Naturally, response time drops as the query progresses into un-cached regions of storage. Our current “usability benchmark” is to consider a million 1 KB events generated per day. On a 16 GB server, around a week’s data will be cacheable, and response time on this will be within a few seconds. Most Seq installations carry a lot fewer events and so will run completely in RAM.
Past the cache bounds, “archival” data is available at a response time a couple of orders of magnitude below this. Optimally, a retention policy will thin out the events past this point, e.g. by deleting “debug” or tracing events, thus bringing response times back up within a similar range.
Optimal in-memory representation
Using the storage layer’s cache meant Seq still had quite a bit of work to do when scanning events to fulfil query results. This work not only added to response time – it also generated garbage that pushed the GC harder, reducing overall performance.
Since we’re now in control of our own caching destiny, in Seq 1.5 we’re free to choose an in-memory representation that’s much closer to our needs when querying. This eliminates all JSON processing and allocation on a per-event basis, and makes it possible to run practically all queries in compiled code.
Schema-sharing
The most exciting outcome of choosing our own in-memory representation is the opportunity we then have to extract common features from events.
When caching raw event data at the storage layer, each “blob” is unique – property names and so-on get stored for every event. If two events are created by the same line of code, thus having the same property names and message template, the storage layer will record two copies of this information.
In RAM, we’re free to share schema information and duplicated values between many events. While the following two events share nothing on disk:
{"Latitude": 25, "Longitude": 134}
{"Latitude": 12, "Longitude": 54}
In the Seq caching layer they’ll share a single schema object:
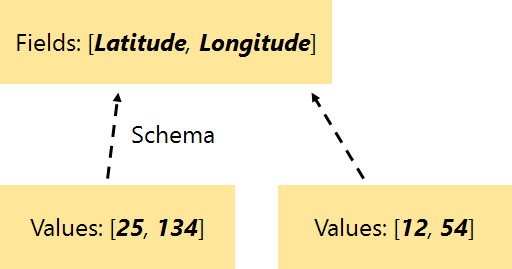
Over many events the savings brought by this approach are significant.
Manageability
Using a single, large data file brought with it a couple of major drawbacks.
Sheer size
First, storing everything in a single large file makes it hard to work with large Seq installations. One user ended up with a single 350 GB default.seq that was impossible to work with in any way. We don’t want to see that again!
In Seq 1.5, files on disk are split into 7-day extents:

The extents are completely self-contained, meaning they can be deleted, moved or backed-up individually.
Compaction time
ESENT data files can only be compacted (shrunk to remove free space) off-line. Coupled with creating a very large data file, this could mean considerable downtime while disk space was reclaimed, and having to use command-line tools to do it was inconvenient.
Compaction would also require enough free disk space to hold a complete copy of the data – a challenge and a waste when a lot of event data is stored.
Using a series of extents on disk means that segments can be compacted one at a time, ideally in the background on a running server, and only the storage for a single extent is required during the compaction process.
The 1.5.5-pre build still relies on a command-line seq compact facility, but storage requirements are lessened and the process is much more responsive. We’ll be working on background compaction for the next preview.
Installing Seq 1.5.5-pre
There are a few things to know before you upgrade to Seq 1.5.5-pre.
The migration process requires approximately the same disk space as is taken by the existing C:\ProgramData\Seq\Data folder. Seq will refuse to migrate or run without this available. After migration is run, the space will be freed and won’t be needed again except to store events.
Running the following commands prior to migration will free as much space as possible for the process:
seq stop
seq compact
Migration from a large Seq 1.4 database can also take considerable time – allowing 10 minutes per million events would give a safe margin; better hardware will move data much faster. If this makes migration prohibitive, and you can’t use retention policies to cut down on event volume beforehand, please email support for help.
After migration completes, it will take a little while for the cache to warm up. If you see an asterisk (*) after the Loading… indicator text, this means events are being scanned in un-cached storage regions. Give it a few more minutes :).
Finally, the new cache is designed for server use and thus consumes as much system memory as it can. If the system comes under memory pressure, it will release memory to compensate. This mightn’t be convenient on all systems – if you’re in this position we’d like to know a bit more about your setup: email us at the address above and we’ll let you know when configuration options are available to control this.
What else is to come from 1.5?
Already included in the current preview are some major improvements to start-up/shut-down time, and some long overdue features such as manual deletion of events. There are several other tickets planned for the full release, and I’ll post some details on those as they land.
How does 1.5.5-pre work for you?
We haven’t published any figures with this post; when Seq 1.5 is ready to ship I’ll make sure we share some 1.4 vs. 1.5 benchmarks, but for the time being we’re looking for real-world usage and feedback to validate the direction we’re taking and provide a qualitative measure of how the changes stack up.
If you’re able to try Seq 1.5, we’d love to hear your impressions. It’s not a production-ready release, but we’ll do our very best to support migration from the preview to RTW when that happens (we’ve migrated our own servers!) so with some small risk it should be fine to use on dev/non-mission-critical systems.
Download it now!
You can grab the installer here.